摘要:数据预处理的四种技术:数据合并,数据清洗,数据标准化,数据转换
只是做自己的学习笔记使用,如有错误请评论区指出。
数据预处理的四种技术:数据合并,数据清洗,数据标准化,数据转换
导包和数据集
工具使用pandas和numpy
1 | import pandas as pd |
查看数据维度以及类型
1 | #查看前五条数据 |
操作训练集中的信息
1 | #统计Title单列元素对应的个数 |
1.合并数据
建立关系表:
data1 = pd.DataFrame({'key1':list('aavde'),'key2':list('asdfs'),'key3':list(str(12345))})
data1 = pd.DataFrame(np.random.rand(3,3),index = list('abc'),columns = list('ABC')) 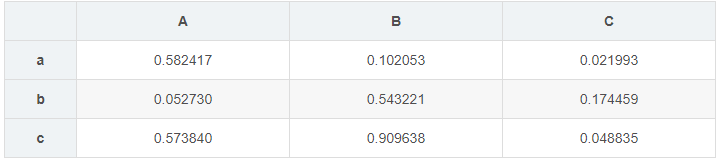
堆叠
1 | #方法一: |
objs 接受用于合并的series,dataframe的组合。以列表的形式,eg:[data1,data2]其中data1和data2为两个二维表
axis 表示堆叠的轴向,默认axis为0,表示纵向堆叠,以行为主的堆叠方式
join 接受inner或outer。表示其他轴向上的索引是按交集还是并集进行合并,默认为outer;outer表示并集,不存在的关系其值用NaN代替;inner表示交集,结果仅返回无空值的行或者列(此处由axis的取值决定,0:列中无空值;1:行中无空值)
ignore_index 接受boolean.表示是否不保留连接轴上的索引,产生一组新索引range(toatal_length)默认为False
verify_intergrity 接受boolean,检查新连接的轴是否包含重复项。如果发现重复项,则引发异常。默认为False
1 | #方法二:利用append实现纵向堆叠,前提是合并的两张表列名应该一致 |
通过主键合并数据
具体实例可见 链接
主键合并就是通过一个或者多个键将两个数据集的行连接起来。类似于sql中的join。
1 | #通用表达 |

可以通过主键合并的情况如下:
1 左右数据有共同的列名,用共同的列名作为主键。此时使用on参数,传入共同的列名。合并后的数据列数为原来数据的列数和减去连接键的数量
2 使用不同列名主键进行合并
3 赋予left_index和right_index参数。使用原本数据的index(行索引)作为主键进行合并
还可以通过不同的列名作为主键进行融合
1 | pd.merge(data_1,data_2,how = 'inner',left_on = 'key1',right_on = 'key2') # 左右的合并主键分别是key1和key2。 |
通过索引为主键
1 | pd.merge(data_1,data_2,how = 'inner',left_index = True,right_index=True) |
join方法
1 | #通用表达 |

2.清洗数据
检测重复值
1 | dataframe.drop_duplicates(subset=None,keep=‘first’,inplace=False) |

检测与处理缺失值
检测
1 | data_null = pd.DataFrame({'key1':[np.nan,1,2,3,4,5,np.nan],'key2':[1,2,3,4,5,6,np.nan]}) |
处理
处理缺失值的方法主要有:删除法,替换法,插值法。
删除缺失值
1 | #其中subset指出需要删除空值的列名,与how属性联动才可以使用 |
上面的thresh属性存在疑问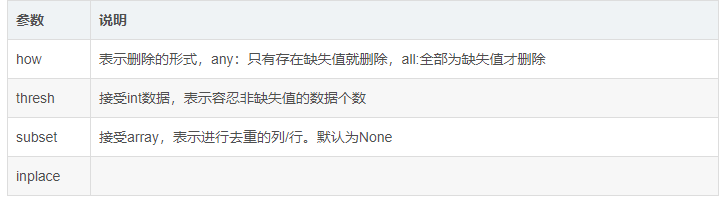
替换缺失值
1 | dataframe.fillna(value = None,method=None,axis=None,inpalce=False,limit=None) |
