摘要:Progressive Self-Supervised Attention Learning forAspect-Level Sentiment Analysis翻译及理解
Progressive Self-Supervised Attention Learning forAspect-Level Sentiment Analysis翻译及理解
1.本文针对神经网络在学习过程中存在的强模式过学习和弱模式欠学习的问题,提出了渐进自监督注意力机制算法,有效缓解了上述问题。主要基于擦除的思想,使得模型能够渐进的挖掘文本中需要关注的信息,并平衡强模式和弱模式的学习程度。在基于方面层次的情感分析三个公开数据集和两个经典的基础模型上测试表明,所提出的方法取得了不错的性能表现。
2.在方面层次的情感分类任务中,经典方法为使用注意力机制来捕获上下文文本中与给定方面最为相关的信息。然而,注意力机制容易过多的关注数据中少部分有强烈情感极性的高频词汇,而忽略那些频率较低的词。
摘要
在方面级别的情感分类(ASC)中,普遍的做法是为优势神经模型配备注意机制,以便获得给定方面每个上下文词的重要性。 但是,这种机制倾向于过分关注少数带有情感极性的频繁单词,而忽略了很少出现的单词。 本文提出了一种针对神经ASC模型的渐进式自我监督注意学习方法,该方法会自动从训练语料库中挖掘有用的注意监督信息,以细化注意机制。特别是,我们对所有训练实例进行迭代的情感预测。 将具有最大注意力权重的上下文单词提取为对每个实例的正确/不正确预测具有积极/误导性影响的上下文单词,然后将该单词本身屏蔽起来以进行后续迭代。 最后,用正则化项削弱了常规训练目标,这使ASC模型可以继续将注意力集中在提取的活动上下文词上,同时减少那些误导对象的权重。对多个数据集的实验结果表明,我们提出的方法产生了更好的注意力机制,从而导致了对两种状态的重大改进 最先进的神经ASC模型。 源代码和经过训练的模型可从https://github.com/DeepLearnXMU/PSSAttention获得。
1.介绍
基于方面的情感分析在该领域中是一项单独的任务,旨在推断出输内容在某一方面的情感极性。
目前该工作的处理模型:占主导地位的ASC模型已发展为基于神经网络(NN)的模型,它可以自动的学习输入内容的情感关系,表现良好。attention机制在该任务中也有着重要的作用。
现存的基于attention的ASC模型有一个重大的缺陷:这种机制倾向于过分关注少数带有情感极性的频繁单词,而忽略了很少出现的单词。
两个模式:“apparent patterns” and “inap-parent patterns”
其中,“明显模式”被解释为带有强烈情绪极性的高频词汇,而“不明显模式”则被解释为训练数据中的低频词汇,神经网络通常会对显示模式的词语过度学习,针对不明显的词语忽视掉。
一个反面例子:
在前三个训练句中,由于语境词“小”经常与消极情绪一起出现,注意机制对其给予了更多的关注,并将包含“小”情绪的句子与消极情绪直接联系起来。这就不可避免地导致了另一个信息上下文单词“crowded”被部分忽略,尽管它也是消极意义上的词语。因此,情绪的神经ASC模型错误地预测最后两个测试句子:在第一个测试中句子,神经ASC模型未能捕获的负面情绪与“拥挤”;同时,在第二个测试句子,注意机制直接关注“小”尽管这样与方面词没有关系。(本次测试样例中的aspect是place??)
在本文中,我们提出了一种针对神经ASC模型的新型渐进式自我监督注意力学习方法。该方法可以自动的递增的从训练语料中获得注意力监督信息,它可以用于指导ASC模型中attention机制的训练。
想法依据:注意权重最大的上下文词对输入句子的情感预测影响最大。因此,在模型训练过程中应考虑正确预测的训练实例的上下文词。 相反,预测错误的训练数据应该被忽视。为此,我们迭代地对所有训练实例进行情绪预测。
大致过程:特别的是,在每次迭代时,我们从每一次训练实例中提取出最大的attention权重去规范attention监督信息,这可以用于规范attention机制的训练:在正确预测的情况下,我们将保留此词以供考虑; 否则,预计该词的注意力下降。然后,我们屏蔽了到目前为止每个训练实例提取的所有上下文词,然后重新进行上述过程以发现更多注意机制的监督信息。 最后,我们用调节器增强标准训练目标,该调节器强制这些挖掘的上下文词的注意力分布与其预期分布相一致。
本文突出贡献:
(1)通过深入分析,指出了目前一般的注意力机制存在的不足。
(2)提出了一种新的神经ASC模型注意监控信息自动提取的增量方法。
(3)我们将我们的方法应用于两个主要的神经ASC模型:记忆网络(MN) 和转换网络(TNet)。几个基准数据集的实验结果证明了该方法的有效性。
2.背景
本节简单给出MN和TNet两个模型的介绍,这两个模型都实现了令人满意的效果。
几个参数介绍:
x= (x1,x2,…,xN) :输入句子文本
t= (t1,t2,…,tT) :给出的目标aspect
y,yp∈{Positive, Negative, Neutral}用于表示真实的标签和预测的标签(即情感极性) )
)
MN模型:先介绍一个方面嵌入矩阵,将每个target aspect的单词tj转换为词向量表示形式,然后定义最终t的词向量表示形式为v(t),作为该词的平均aspect词嵌入向量。 同时,另一个嵌入矩阵用于将每个上下文单词xi投影到连续存储的内存中,用mi表示。然后,使用内部attention机制生成句子x的与aspect相关的情感语义表示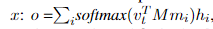
其中M是一个attention矩阵,并且hi是从上下文词中引出的xi的最终语义表示,被从上下文词嵌入矩阵导出。 最后,我们使用完全连接的输出层基于o和v(t)进行分类。
TNet:三个组件
(1)底层是Bi-LSTM,它将输入x转换为上下文化的单词表示形式 (此处有疑问)
(即Bi-LSTM的隐藏状态)。
(2)中间部分作为整个模型的核心,包含L层上下文保持转换(Context-Preserving Transformation:CPT),其中单词表示形式更新为)。CPT层的关键操作是特定于目标的转换。它包含另一个Bi-LSTM,用于通过注意机制生成v(t),然后将v(t)合并到单词表示中。此外,CPT层还配备了上下文保存机制(Context-Preserving Mechanism: CPM)来保存上下文信息和学习更抽象的单词级特性。最后,我们得到了单词级语义表示
(3)最上层是CNN层,用于生成与方面相关的句子表示o进行情感分类。
在这项工作中,我们考虑了原始TNet的另一种替代方案,该替代方案用注意力机制替换了最顶层的CNN,以产生与方面相关的句子表示形式为:o = Atten(h(x),v(t))。 在第4节中,我们将研究原始的TNet及其配备注意机制的变体的性能,该机制由TNet-ATT表示。
训练对象:上述两种模型都以gold-truth情绪标签的负对数可能性为研究对象
3.本文方法
在本节中,我们首先描述了方法背后的基本认识,然后提供了其详细信息。最后,我们阐述了如何将挖掘的监督信息纳入注意机制到神经ASC模型中。我们的方法只适用于神经ASC模型的训练优化,对模型测试没有任何影响
3.1基本介绍(直观理解)
我们的方法的基本直觉源于以下事实:在注意力ASC模型中,每个上下文单词在给定方面的重要性主要取决于其关注权重。 因此,关注度最大的上下文词对输入句子的情感预测影响最大。 因此,对于训练句子,如果ASC模型的预测是正确的,我们认为继续关注该上下文词是合理的。 相反的话,应该降低该上下文词的注意力权重。
但是,如前所述,具有最大注意力权重的上下文词通常是具有强烈情感极性的上下文词。 它通常在训练语料库中频繁发生,因此在模型训练过程中往往会过分考虑。 这同时导致对其他上下文单词,尤其是具有情感极性的低频单词的学习不足。 为了解决该问题,一种直观且可行的方法是在重新研究训练实例的其余上下文词的效果之前,首先屏蔽该最重要的上下文词的影响。 在这种情况下,可以根据它们的注意力权重发现其他具有情感极性的低频上下文词
3.2算法细节
我们提出了一种新颖的增量方法,可以从训练实例中自动挖掘有影响力的上下文词,然后可以将其用作神经ASC模型的注意监督信息。(说好几遍了。。。)
首先使用初始训练语料库D进行模型训练,然后获得初始模型参数$\Theta ^{(0)}$(第1行)。 然后,我们继续训练K迭代模型,在其中可以迭代地提取所有训练实例的有影响力的上下文单词(第6-25行)。 在此过程中,对于每个训练实例(x,t,y),我们引入初始化为∅的两个单词集(第2-5行),以记录其提取的上下文单词:(1)$S_{a}(x)$包括对 x的情绪预测有积极作用的上下文单词。每个$S_{a}(x)$的单词将被考虑更加细化的模型训练中(2)$S_{m}(x)$包含具有误导作用的上下文词,预期其注意力权重将降低。 具体来说,在第k次训练迭代中,我们采用以下步骤来处理(x,t,y):
在第1步中,我们首先应用上一次迭代的模型参数θ(k-1)生成纵横表示v(t)(第9行)。 重要的是,根据sa(x)和sm(x),我们然后屏蔽所有先前提取的x的上下文词以创建新的句子x’,其中每个被屏蔽的词都用特殊标记“ 〈mask〉”替换(第10行) 以此方式,在x’的情感预测期间将屏蔽这些上下文词的影响,因此可以从x’提取其他上下文词。 最后我们得到单词之间的关系: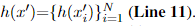
在第2步中,基于v(t)和h(x’),利用θ(k-1)预测x’作为yp的情感极性(第12行),其中单词级注意力权重分布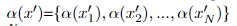
权重分布由下式得到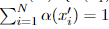
在步骤3中,我们使用熵E(α(x’) )以测量α(x’)的方差(第13行),有助于确定影响上下文上下文词的存在,以进行x’的情感预测: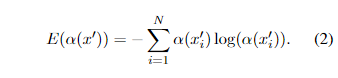
如果E(α(x’))小于阈值Cα(第14行),我们认为存在至少一个上下文词,对x’的情感预测有很大影响。 因此,我们提取具有最大注意权重的上下文词x’m(第15-20行),将其用作注意监督信息以完善模型训练。 具体来说,我们针对x’的不同预测结果采取两种策略来处理x’m:如果预测正确,我们希望继续关注x’m,将其添加到sa(x)中(第16-17行); 否则,我们期望减少x’m的注意力权重,因此将其包括到sm(x)中(第18-19行)。
在第4步中,我们将t,x’和y组合成一个三元组,并将其与收集到的三元组合并,以形成一个新的训练语料库D(k)(第22行)。 然后,我们将D(k)做出影响级以继续更新模型参数以进行下一次迭代(第24行)。 通过这样做,我们使模型具有适应性,可以发现更多有影响力的上下文词。
通过上述步骤的集合,我们可以提取所有训练实例的有影响力的上下文词。 表2说明了表1中显示的第一句话的上下文词挖掘过程。在此示例中,我们轮换着迭代这提取下面三个词“small”, “crowded”和“quick”。前两个词包含在insa(x)中,最后一个包含在insm(x)中。最后,每个训练实例的提取上下文词将被包含到D中,形成具有注意力监控信息的最终训练语料Ds(第26-29行) ,这将用于进行最后的模型训练(第30行)。
3.3attention监督信息模型的训练
 )
)
4、实验部分
数据集:我们将提出的方法应用于MN和TNet-ATT(参见第2节),并在三个基准数据集上进行了实验:LAPTOP, REST和TWITTER。在数据集中,已经提供了每个句子的目标方面。 此外,我们删除了一些带有冲突情绪标签的实例(Chen et al。,2017)。 表3列出了最终数据集的统计信息。(上面的表)
对比模型:我们将两个增强的ASC模型称为MN(+ AS)和TNet-ATT(+ AS),并将它们与MN,TNet和TNet-ATT进行比较。 请注意,我们的模型需要进行额外的K + 1次迭代训练,因此,我们还将它们与上述进行了额外的K + 1次迭代训练的模型进行了比较,分别表示为MN(+ KT),TNet(+ KT)和TNet-ATT(+ KT)。此外为了研究不同种attention监督信息的影响,我们还列出了MN(+ ASa)和MN(+ ASm)的性能,它们分别仅利用了sa(x)和sm(x)的上下文词,并且对于TNet-ATT(+ ASa)和TNet-ATT(+ ASm)都是相同的效果。
训练细节:我们使用预先训练的GloVe vectors初始化矢量尺寸为300的单词嵌入。对于词汇量不大的单词,我们从均匀分布[-0.25,0.25]中随机采样其嵌入。 此外,我们在[-0.01,0.01]之间均匀初始化了其他模型参数。为缓解过度拟合,我们在LSTM的输入单词嵌入和最终与方面相关的句子表示上采用了dropout策略。 (Kingma and Ba,2015)被作为优化器,学习率为0.001。
在实施我们的方法时,我们根据经验将最大迭代数K为5,方程3中的γ设置为LAPTOP数据集上的0.1,REST数据集上的0.5,TWITTER数据集上为0.1。 所有超参数均为20%随机调整的训练数据。最后,我们使用F1-Macro和准确性作为我们的评估方法。
4.1Effects of $\epsilon _{a}$
$\epsilon _{a}$是一个非常重要的超参数,它控制挖掘注意超信息的迭代次数(请参见算法1第14行)。 因此,在这组实验中,我们将$\epsilon _{a}$从1.0更改为7.0,每次递增1,以研究其对我们的模型在验证集上的性能的影响。图3和图4显示了实验 不同模型的结果。 具体来说,$\epsilon _{a}$= 3.0的MN(+ AS)达到最佳性能,而当$\epsilon _{a}$= 4.0时,获得了TNet-ATT(+ AS)的最优性能。 我们观察到α的增加并没有导致进一步的改进,这可能是由于提取了更多嘈杂的上下文词所致。由于这些结果,我们分别将MN(+ AS)和TNet-ATT(+ AS)的$\epsilon _{a}$设置为3.0和4.0。
4.2 总体结果
表4提供了所有实验结果。 为了增强我们实验结果的说服力,我们还在同一数据集上显示了MN(Wang等人,2018)和TNet(Liet等人,2018)先前报告的得分。 根据实验结果,我们可以得出以下结论:
首先,我们重新实现的MN和TNet均与(Wang等人,2018; Li等人,2018)中报道的原始模型相当。 这些结果表明,我们重新实现的基准具有竞争力。 当我们用注意机制替换TNet的CNN时,TNet-ATT稍逊于TNet。 此外,当我们在这些模块上执行附加的K + 1迭代训练时,它们的性能并没有显着改变,这表明仅增加训练时间就无法增强神经ASC模型的性能。
其次 在MN和TNet-ATT中提出的方法中,上下文单词in sa(x)比in sm(x)更有效,这是因为正确预测的训练实例的比例大于不正确训练实例的比例。 此外,MN(+ ASa)和MN(+ ASm)之间的性能差距比TNet-ATT的两个变体之间的性能差距要大。 一个潜在的原因是TNet-ATT的性能优于MN,这使TNet-ATT可以产生更正确预测的训练实例。 与MN相比,这反过来给TNet-ATT带来了更多关注的监督。
最后,当我们同时使用两种注意力监督信息时,无论哪种算法,测试集中MN(+ AS)在所有方面都明显优于MN。尽管我们的TNet-ATT稍逊于TNet,但TNet-ATT(+ AS)仍大大超过TNet和TNet-ATT。 这些结果强有力地证明了我们方法的有效性和普遍性。
4.3案例研究
为了了解我们的方法如何改进神经ASC模型,我们深入分析了TNet-ATT和TNet-ATT(+ AS)的注意力结果。 已经发现,我们提出的方法可以很好地解决上述两个问题。
表5提供了两个测试案例。 TNet-ATT错误地将第一个测试句子的情绪预测为中立。 这是因为上下文词“不舒服”仅出现在两个带有负极性的训练实例中,这分散了对其的注意力。 使用我们的方法时,在这两种情况下,“uncomfortable”的平均注意力权重增加到基线的2.6倍。 因此,TNet-ATT(+ AS)能够为该上下文词分配更大的关注权重(0.0056→0.2940),从而导致对第一个测试句子的正确预测。 对于第二个测试语句,由于上下文单词“ cute”出现在大多数具有正极性的训练实例中,因此TNet-ATT直接将注意力集中在该单词上,然后错误地将情感感知预测为积极。 采用我们的方法,在具有神经或负极性的训练实例中,“可爱”的注意力权重显着降低。 具体而言,在这些情况下,“可爱”的平均权重降低到原始值的0.07倍。 因此,TNet-ATT(+ AS)将较小的权重(0.1090→0.0062)分配给“cute”,并获得正确的情感预测。
5.相关工作
最近,已经证明神经模型在ASC上是成功的。 例如,由于具有多重优势(例如更简单,更快速),具有注意力机制的MN被广泛使用(Tang等; Wang等)。另一种流行的神经模型是LSTM,它也涉及 一个关注机制来明确捕捉每个上下文词的重要性(Wang等人,2016)。 总的来说,注意力机制在所有这些模型中都起着至关重要的作用。
跟随这种趋势,研究人员诉诸了更为复杂的注意力机制来重新完善神经ASC模型。 Chen 提出了一种多注意机制来捕获相隔很远距离的情感特征,以使其对不相关的信息更具鲁棒性。 Ma等人为ASC设计了一个交互式注意力网络,其中引入了两个注意力网络来对目标和上下文进行交互建模。 Liu 提出对ASC利用多种注意力:一个是从给定方面的左上下文获得的,另一个是从给定方面的右上下文获得的。 最近,ASC也探索了基于变换的模型(Li等,2018),注意力机制被CNN取代。
与这些工作不同的是,我们的工作与引入注意力监督以精炼的研究相一致。 注意机制,已成为事件检测(Liuet等人,2017),机器翻译(Liu等人,2016)和警察杀人检测(Nguyen and Nguyen,2018)等多个基于NN的NLP任务中的热门研究主题。 )。 但是,这种有监督的注意力获取是很费力的。 因此,我们主要致力于自动采矿监督信息,以获取神经ASC模型的注意机制。从理论上讲,我们的方法与这些模型正交,因此我们将对这些模型的适应性留作以后的工作。
我们的工作受到两个最新模型的启发:其中一个时(Wei等人,2017)提出使用分类阳离子网络逐步消除区分对象区域以解决弱监督语义分割问题,另一个是(Xu等人,2018) 其中提出了一种与全局信息集成的辍学方法,以鼓励模型挖掘不明显的特征或模式进行文本分类。 据我们所知,我们的工作是第一个探索自动挖掘ASC注意监控信息的人。
6.总结与工作计划
在本文中,我们探索了如何自动挖掘监督信息,以用于神经ASC模型的注意机制。 通过深入的分析,我们首先指出了ASC注意机制的缺陷:一些带有情感极性的常用词往往被过度学习,而频率较低的词却缺乏足够的学习能力。 然后,我们提出了一种新的方法来自动地、增量地挖掘神经ASC模型的注意监督信息。 这些挖掘的信息可以通过正则化项进一步用于优化模型训练。 为了验证我们方法的有效性,我们将我们的方法应用于两个主要的神经ASC模型,实验结果表明我们的方法显着改善了这两个模型的性能。 因此,我们计划将我们的方法扩展到具有注意机制的其他神经NLP任务,例如神经文档分类(Yang等)和神经机器翻译(Zhang等)。