论文名称:Unsupervised Machine Translation Using Monolingual Corpora Only
作者: Guillaume Lample / Ludovic Denoyer /Marc Aurelio Ranzato
发表时间:2018/4/30
论文链接:https://arxiv.org/pdf/1711.00043v1.pdf
代码链接:https://github.com/facebookresearch/MUSE 以及 https://github.com/facebookresearch/fastText
发现一篇很详细的翻译笔记:地址
在此仅作自己的学习笔记总结:
1 论文概述
本文目的:希望不利用平行语料库实现机器翻译,本文提出的模型,仅需要两个语种各自的单语种语料数据集,并将2者映射到同一隐空间中。模型主要是学习通过从共享的隐特征向量空间中重建这两种语种。
模型的两个原则:第一个原则:这个模型必须能够从一个带噪声的输入中重建出一个给定语种的句子,如标准去噪自动编码器。第二个原则:该模型能够在目标域中对带有噪声的翻译句子重建出源句,反之亦然。
模型重要思想:关键思想是在两种语言(或领域)之间建立共同的潜在空间,并通过根据两个原则在两个领域中进行重构来学习翻译:(i)该模型必须能够从特定语言中重构给定语言的句子。 噪声版本,如标准降噪自动编码器中的那样(Vincent等,2008)。 (ii)在目标域中相同句子经过嘈杂翻译的情况下,该模型还学会重建任何源句,反之亦然。 对于(ii),翻译后的句子是通过使用反向翻译程序获得的(Sennrich et al。,2015),即 通过使用学习的模型将源句子翻译到目标域。 除了这些重建目标之外,我们使用对抗性正则化术语来约束源句和目标句的潜在表示形式以使其具有相同的分布,从而该模型尝试欺骗鉴别器,同时对鉴别器进行训练以识别给定潜在句子表示形式的语言(Ganin 等人,2016年)。 然后反复重复此过程,从而产生质量提高的翻译模型。 为了保持我们的方法完全不受监督,我们使用了一个简单的无监督翻译模型来初始化我们的算法,该模型基于一个句子的逐词翻译,并使用源自相同单语数据的双语词典(Conneau et al。,2017)。 通过仅使用单语数据,我们就可以将两种语言的句子编码到相同的特征空间中,并且从那里,我们还可以使用任何一种语言进行解码/翻译; 参见图1的说明: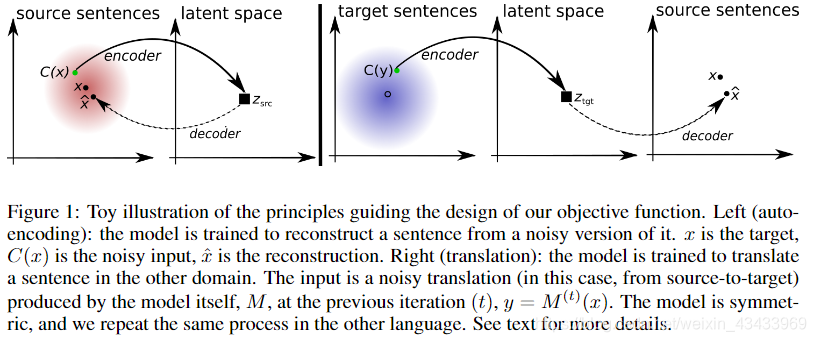
x和z分别代表encode和decode两端的输入:
在本文中,我们注意使用equence-to-sequence模型。 编码器是双向LSTM,它返回隐藏状态序列z =(z1,z2,…,zm)。 在每个步骤中,作为LSTM的解码器将采用先前的隐藏状态,当前字和上下文矢量由编码器状态上的加权总和给出。
方法总览:给定相同或其他域中相同句子的嘈杂版本,我们通过重构特定域中的句子来训练编码器和解码器。
2 模型各个模块
噪声模型训练:如何通过噪声语句训练自动编码
本文采用与去噪自编码器(DAE)相似的策略将噪声添加到输入句子中。
训练的目标函数为:

跨域训练:
如何实现源语句与翻译语句之间 的映射?
(1)从源语种中采样出一个句子x,在l2中生成此时的翻译结果。这个 翻译结果是基于当前翻译模型M生成的,所以可以表示为y=M(x)
(2)再对该翻译结果y进行加噪,得到corrupted的C(y)。目标是学习能够在C(y)中重建出x的encoder和decoder。所以这里的加噪在C(y)这里。
(3)根据C(y)重建x
此时的损失目标函数为: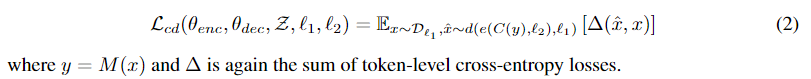
对抗训练:还未理解
当 encoder 所输出的特征位于同一个空间而不管输入的句子是何语种时,那么 decoder 就有可能无视encoder中的输入句子而实现decode为特定语种。其实,隐空间就像是一个标准,在这个标准上可以任意转为其他格式(这里特指语种),而其他语种需要统一转到该隐空间,进行标准统一。
但是需要注意,decoder 在目标域中生成句子时仍然可能有错误的翻译。限制 encoder 在同一特征空间映射两种语言,并不意味着句子之间存在严格的对应关系。所幸的是,前面介绍的公式2中跨域训练的损失减轻了这种担忧。最近关于双语词典的研究表明,这种约束在词级别(word level)上是非常有效的,这表明只要这两种隐表征在特征空间上表现出较强的结构性,那么这种约束在句子层面( sentence level)上也可能有效。

下图为本文最重点的图,描述了模型是如何工作的: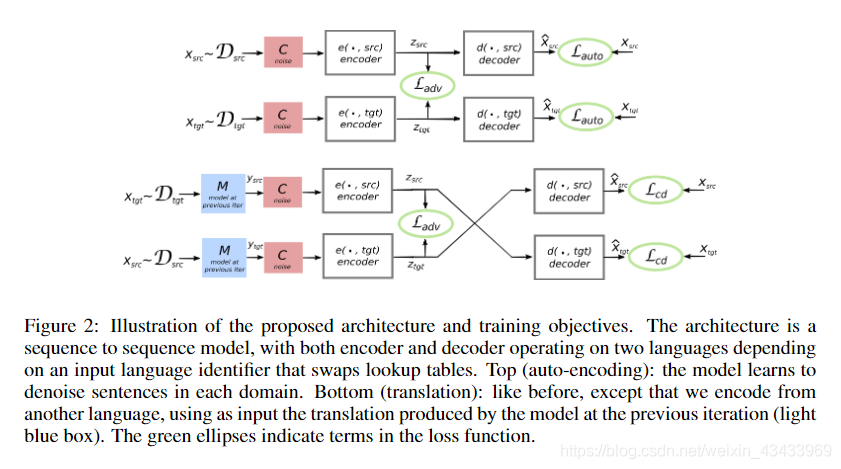
模型主要包含原文重建和译文重建两个部分。图中上面是原文重建部分,使用的是自编码器,输入源语言最后的输出仍然是源语言。下面是译文重建部分,给定源语言之后,先经过M模型翻译为对应的译文,然后经过encoder-decoder模型翻译回原文
3 训练
3.1 迭代训练
最终学习算法在算法1中进行了描述,该模型的一般体系结构如图2所示。如前所述,我们的模型依赖于从初始翻译模型M(1)(第3行)开始的迭代算法。根据等式2的跨域损耗函数的需要,此函数用于转换可用的单语数据。在每次迭代中,通过最小化等式4 –的损耗来训练新的编码器和解码器(第7行)。 然后,通过组合生成的编码器和解码器来创建新的翻译模型M(t + 1),然后重复该过程。
为快速启动该过程,M(1)使用学习到的并行词典对每个句子进行逐词翻译,使用Conneau等人提出的仅利用单语数据的无监督方法。
4 实验
数据集:WMT’14 English-French、WMT’14 English-French、Multi30k-Task1
4.1 Baselines
Word-by-word translation (WBW):逐词翻译系统。该系统对相关语种,比如English-French 性能较好,但是在相距较远的语种如English-German表现较差。
Word reordering (WR):WR系统是对WBW的结果用LSTM模型做了一次词序调整。由于难以穷尽一个句子中单词(有些句子单词量大于100个)的全部排列组合,这里仅仅考虑相邻单词之间的互换操作。在实验过程中选择最好的交换,迭代10次。这个baseline仅仅用于 WMT dataset ,这是因为 WMT dataset 有足够多的数据可以训练一个较好的语言模型。
Oracle Word Reordering (OWR):使用参考,我们仅使用WBW给出的字词就能产生最佳的生成效果。 这种方法的性能是任何模型都可以完成的,而无需替换单词。
Supervised Learning:考虑了与我们完全相同的模型,但是在监督下进行训练,在原来的平行句上使用了标准的交叉熵损失。
5 相关工作
与我们类似的工作是Shen等人的非平行文本样式转换方法。 作者考虑了序列到序列模型,在该模型中,赋予解码器的潜在状态也被馈送到鉴别器。 编码器与解码器一起训练以重建输入,但也愚弄了鉴别器。 作者还发现,训练两个鉴别器(一个用于源,一个用于目标域)是有益的。 然后,他们训练了解码器,以使在特定域中的句子解码过程中,根据各自的区分器无法区分出重复的隐藏状态。
在此之前,Hu等人训练了变分自动编码器(VAE),其中解码器输入是非结构化潜在向量的级联,以及表示要生成的句子属性的结构化代码。 鉴别器在解码器的顶部被训练以对所生成句子的标签进行分类,而解码器被训练为满足该鉴别器。 由于解码过程的不可微性,在每个步骤中,其解码器都将在上一步中预测的概率向量作为输入。
也许,最相关的先前工作是由He等人完成的。 (2016b),他实际上是直接针对3.2节中提出的模型选择指标进行了优化。 他们的方法的一个缺点(尚未应用到完全无人监督的环境中)是,它需要使用效率非常低的基于强化学习的方法,通过离散预测的顺序向后传播。 在这项工作中,我们改为建议a)使用对称体系结构,以及b)在训练目标与源之间的翻译时将源与目标之间的翻译冻结,反之亦然。通过交替此过程,我们使用完全可区分的模型进行操作,并且我们有效地收敛。
6 总结
我们提出了一种新的神经机器翻译方法,其中仅使用单语数据集学习翻译模型,而句子或文档之间没有任何对齐。 我们方法的原则是从简单的无监督逐词翻译模型开始,并基于重构损失来迭代地改进此模型,并使用鉴别器来对齐源语言和目标语言的潜在分布。 我们的实验表明,我们的方法无需任何形式的监督就能学习有效的翻译模型